Replikation – Protein-Biosynthese
Verdopplung der Erbinformation, Replikation der DNA
Damit bei einer Zellteilung, zum Beispiel bei der Mitose, jede Tochterzelle die gleiche Erbinformation erhält, muss die DNA vorher verdoppelt werden. Diesen Vorgang nennt man Replikation.
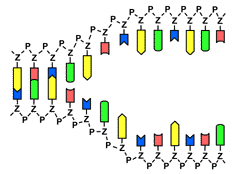
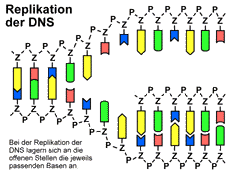
Zuerst wird der Doppelstrang der DNA durch das Enzym Helicase an den Wasserstoffbrücken geöffnet. Dabei trennen sich die beiden Stränge wie ein sich öffnender Reißverschluss, so dass zwei Einzelstränge entstehen. Jeder dieser Einzelstränge dient nun als Vorlage (Matrize) für den Aufbau eines neuen Stranges. An die freiliegenden Basen lagern sich durch das Enzym DNA-Polymerase nach dem Schlüssel-Schloss-Prinzip immer die jeweils passenden Basen an: Adenin (A) paart sich immer mit Thymin (T) und Guanin (G) paart sich immer mit Cytosin (C). Am Ende liegen zwei Doppelstränge vor, die identisch mit der ursprünglichen DNA sind.
Vom Gen zum Protein, die Protein-Biosynthese
Während bei der Replikation die DNA verdoppelt wird, dient sie bei der Protein-Biosynthese als Bauanleitung für die Herstellung von Eiweißen (Proteinen). Proteine steuern fast alle Vorgänge in der Zelle – sie bilden Enzyme, Strukturbausteine, Transportstoffe und vieles mehr.
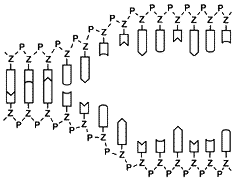
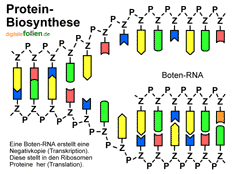
Damit die Information der DNA genutzt werden kann, muss sie zunächst in eine andere Form übertragen werden. Dies geschieht in zwei Schritten: Bei der Transkription öffnet sich die DNA an der Stelle, wo sich die Informationen für ein Protein befinden. Das Enzym RNA-Polymerase liest einen der beiden DNA-Stränge ab und baut daraus eine Negativkopie, die Boten-RNA (m-RNA oder Messenger-RNA) genannt wird. Dabei werden die komplementären Basen nach dem bekannten Schlüssel-Schloss-Prinzip verknüpft – mit Ausnahme einer kleinen Änderung: In der RNA wird Uracil (U)
Je drei aufeinanderfolgende Basen der Boten-RNA bilden einen Triplettcode, der Codon genannt wird. Mit vier Basen sind 64 verschiedene Codon-Varianten möglich. Jedes Codon steht für eine bestimmte Aminosäure. Da es aber nur 20 verschiedene Aminosäuren gibt, werden einige Aminosäuren durch mehrere, verschiedene Codons gebildet – ein Schutzmechanismus gegen Lesefehler. Manchen Aminosäuren wie Arginin sind sechs verschiedene Codons zugeordnet, anderen nur zwei (siehe Codonsonne). Dann gibt es auch noch Codons für Start und Stopp. Der genetische Code wird von fast allen Lebewesen gleich gelesen. Die Codonsonne wird von innen nach außen gelesen: Lysin (Lys) ist zum Beispiel mit AAA oder mit AAG codiert.
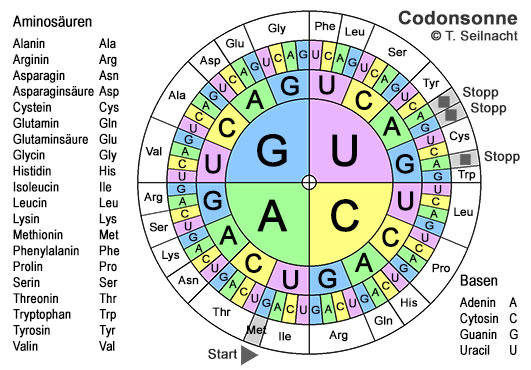
Im Zellplasma befinden sich neben der m-RNA auch Enzyme, alle notwendigen Aminosäuren als Protein-Bausteine und verschiedene Arten von Transfer-RNA (t-RNA). Spezielle Enzyme verbinden im Zellplasma die passenden Aminosäuren mit ihrer transfer-RNA. Jede Transfer-RNA ist auf eine bestimmte Aminosäure spezialisiert und bringt diese zu den Ribosomen. Diese lesen Codon für Codon aus der m-RNA ab und verbinden dabei die Aminosäuren, die von den Transfer-RNA's herangeschafft werden, zu einer Kette. Sie beginnen beim Startcodon und hören beim Stoppcodon auf. Sobald das Protein vollständig gebaut ist, löst es sich vom Ribosom und faltet sich dann in seine typische räumliche Struktur. Erst dann kann es seine Aufgabe in der Zelle übernehmen. Die Mehrzahl von Helix nennt man übrigens Helices.

Tool: Proteinmaker für Word
Mit diesem nützlichen kleinen Tool kann man aus den Bausteinen der Aminosäuren Peptide oder Proteine in der Primärstruktur bauen. Es stehen mehrere Darstellungsformen in Kreisen, Kästchen und farblichen Hinterlegungen zur Auswahl, und man kann zwischen den offiziellen Symbolen mit einem oder mit drei Buchstaben für die Aminosäuren auswählen.
Proteinmaker: doc docx
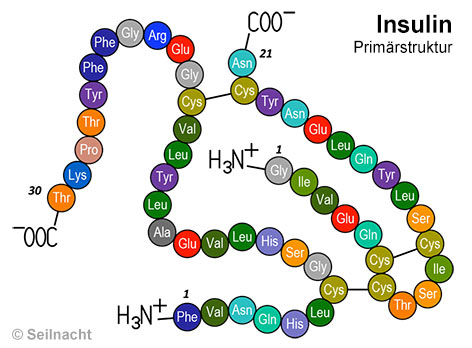
Als Beispiel dient die mit dem Proteinmaker erstellte Grafik eines Peptids, die die Primärstruktur des menschlichen Insulins mit den protonierten und deprotonierten Enden darstellt. Die A-Kette (rechts) besteht aus 21 Aminosäure-Bausteinen, die B-Kette (links) aus 30 Bausteinen. Die Aminosäuren sind untereinander durch Peptidbindungen verknüpft, die in diesem Modell nicht dargestellt sind. Chemisch korrekt formuliert handelt es sich also nicht mehr um die einzelnen Aminosäuren, sondern um die Aminosäure-Reste, weil bei der Bildung einer Peptidbindung Wasser abgespalten wird. Es sind drei Disulfidbrücken am korrekten Ort eingezeichnet (A6–A11, A7–B7, A20–B19). Diese kovalenten Bindungen entstehen aus dem jeweiligen Schwefelatom von je zwei Cystein-Bausteinen. In älteren Schulbüchern wird manchmal bei A21 Glycin (Gly, G) angegeben, dies ist aber falsch, es ist nur beim Rinderinsulin enthalten. Beim Humaninsulin sitzt dort – wie eingezeichnet – Asparigin (Asn, N).
In dieser Liste der Aminosäuren sind die international gültigen Dreibuchstabencodes und die Einbuchstabencodes der IUPAC sowie die wichtigsten Haupteigenschaften aufgeführt. Ein Kreis nach dem Namen bedeutet, dass das Aminosäuremolekül zu den Aromaten gehört und einen Benzolring enthält. Ein „S“ bedeutet, dass im Molekül ein Schwefelatom chemisch gebunden ist:
Aminosäure Code Code Polarität Base/Säure
Alanin Ala A unpolar neutral Arginin Arg R polar basisch Asparagin Asn N polar neutral Asparaginsäure Asp D polar sauer Cystein S Cys C polar neutral Glutamin Gln Q polar neutral Glutaminsäure Glu E polar sauer Glycin Gly G unpolar neutral Histidin His H polar schwach basisch Isoleucin Ile I unpolar neutral Leucin Leu L unpolar neutral Lysin Lys K polar basisch Methionin S Met M unpolar neutral Phenylalanin o Phe F unpolar neutral Prolin Pro P unpolar neutral
Serin Ser S polar neutral Threonin Thr T polar neutral Tryptophan o Trp W schwach polar neutral Tyrosin o Tyr Y polar neutral Valin Val V unpolar neutral
Die Eigenschaften lassen sich aus den Seitenketten (oft auch „Rest“ genannt) ableiten. Wenn die Seitenkette im Molekül nur C- und H-Atome enthält, ist sie unpolar, dann verhält sich die Aminosäure im Wasser hydrophob und ist nicht wasserlöslich. Bei im Wasser neutral reagierenden Aminosäuren hebt eine sauer reagierende Carboxy-Gruppe im Molekül eine basisch reagierende Aminogruppe auf. Der saure Charakter von Glutaminsäure (2-Aminopentandisäure) oder auch von Aspariginsäure (2-Aminobutandisäure) begründet sich im Vorhandensein einer zweiten Carboxy-Gruppe. Im Gegensatz dazu begründet sich der basische Charakter einer Aminosäure im Vorhandensein einer zweiten Aminogruppe im Molekül, zum Beispiel beim Lysin (2,6-Diaminohexansäure).